À propos
Data Engineer spécialisé en conception de pipelines de données et architectures Big Data. J’ai travaillé sur des projets concrets en traitement distribué avec Spark et en ingestion temps réel avec Kafka, avec un objectif clair : construire des systèmes fiables, performants et scalables.
Mon approche est orientée production : comprendre le besoin métier, modéliser la donnée, puis concevoir et déployer des pipelines optimisés et maintenables.
Big Data & Streaming
Traitement de données à grande échelle et streaming en temps réel
Data Engineering
Conception de pipelines ETL, modélisation et orchestration
Cloud & Déploiement
Industrialisation et déploiement de solutions data
Expériences & Projets
Une sélection de projets en Data Engineering, Big Data et traitement de données à grande échelle
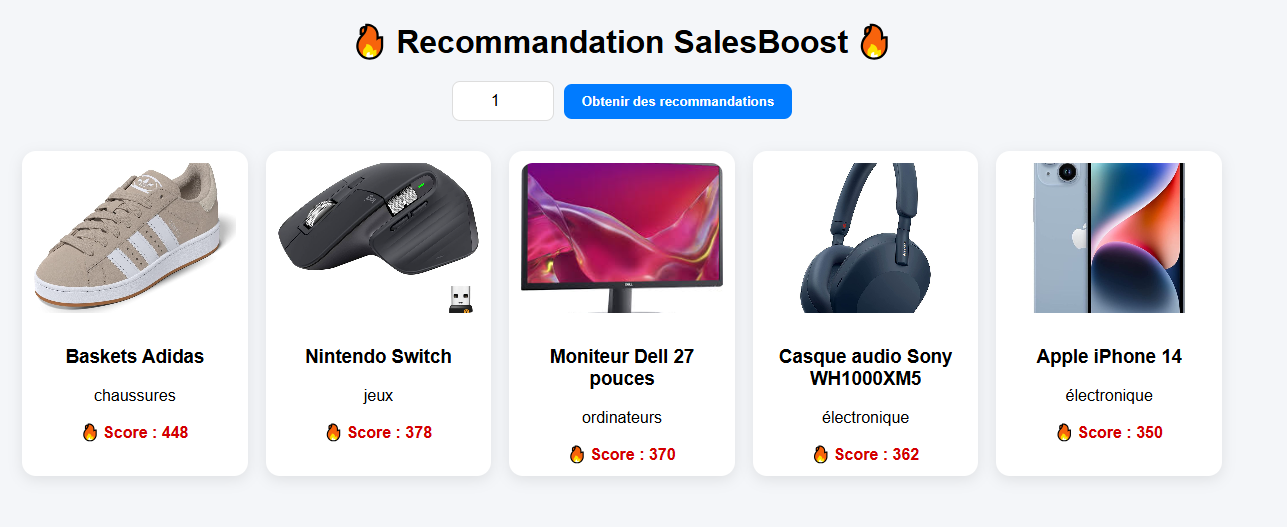
Data Engineer – Système de recommandation temps réel (SalesBoost)
Conception d’un système de recommandation e-commerce en temps réel basé sur une architecture
Big Data complète.
Pipeline temps réel : ingestion des événements utilisateurs avec Kafka, traitement distribué
avec Spark Streaming
et calcul de scores dynamiques en continu.
Stockage optimisé avec Redis (faible latence) et MongoDB, exposition via API FastAPI et
interface React.
Simulation de trafic utilisateur pour tester la scalabilité et valider les performances du
système en conditions réelles.
Data Engineer – Pipeline ETL & Data Warehouse Snowflake (GCP)
Développement d'un pipeline ETL production-ready de bout en bout
pour des données e-commerce réelles (100k+ commandes Kaggle).
Extraction Python vers Snowflake (staging), transformations dbt
en 3 couches (staging → intermediate → marts) et modélisation
en schéma en étoile sur Snowflake (GCP).
Orchestration avec Airflow (DAG quotidien : extract → dbt run →
dbt test → notification), avec optimisation SQL (-53% de temps
d'exécution).
Dashboard analytique interactif avec Streamlit connecté
directement à Snowflake.

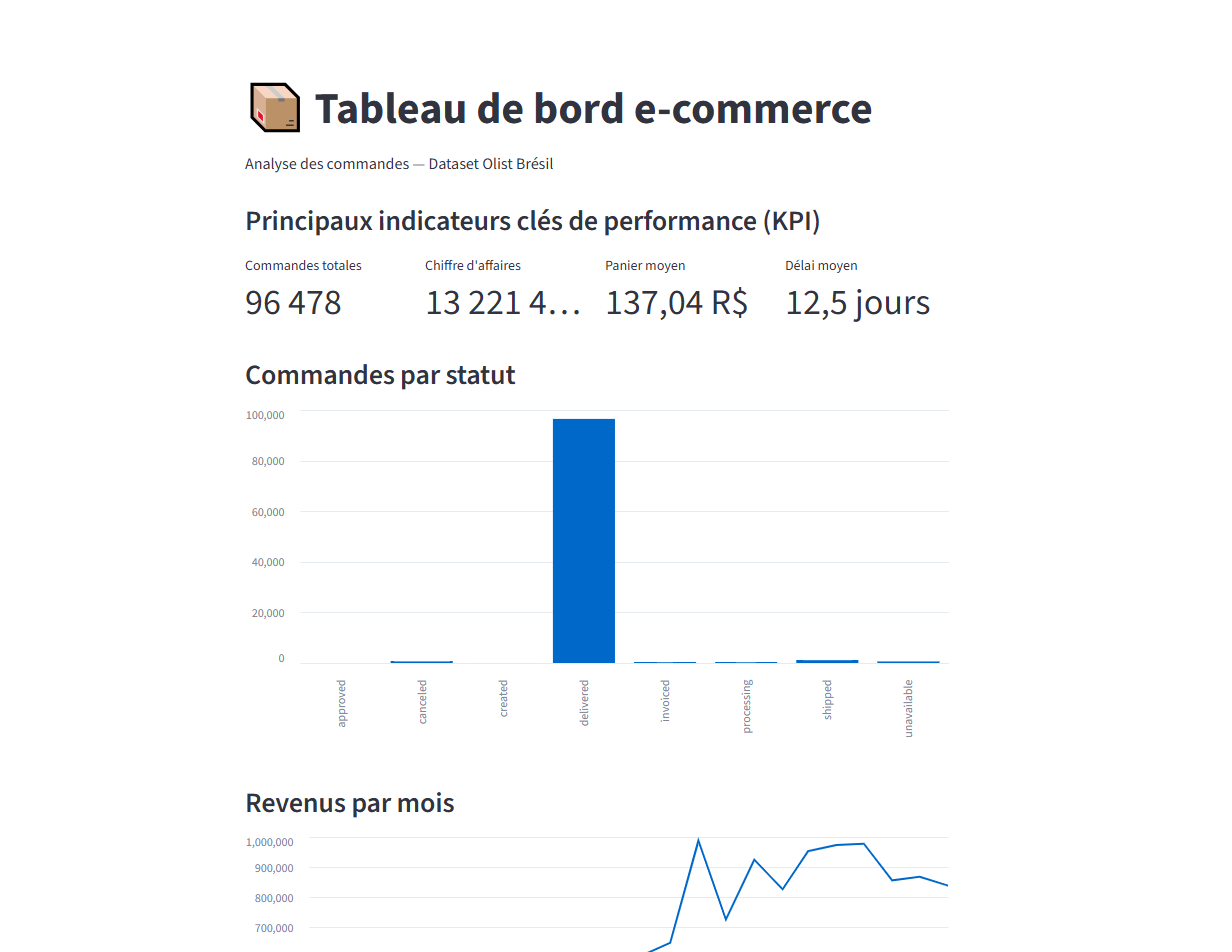
Data Engineer – Pipeline ETL E-commerce temps réel (Olist)
Conception et développement d'un pipeline de données end-to-end pour le traitement
et l'analyse de données e-commerce (dataset Olist Brésil).
Ingestion temps réel avec Kafka : lecture ligne par ligne des CSV et envoi dans
3 topics (commandes, clients, produits). Chargement dans PostgreSQL via un consumer
Python avec insertion par batch.
Validation qualité automatique avec Great Expectations (12 règles : unicité,
not null, valeurs acceptées). Transformation et modélisation en schéma en étoile
avec dbt (6 modèles, 10 tests, 100% PASS).
Orchestration automatique de l'ensemble du pipeline en 7 tâches séquentielles
avec Airflow. Environnement entièrement conteneurisé avec Docker Compose
(5 services : PostgreSQL, Kafka, Zookeeper, Airflow webserver, Airflow scheduler).
Autres projets
Projets complémentaires en data engineering, automatisation et traitement analytique

Plateforme d’analyse et prédiction des performances olympiques
Développement d’une plateforme d’analyse et de prédiction autour des Jeux Olympiques
2024.
Traitement distribué des données avec Apache Spark, entraînement d’un modèle de prédiction
avec TensorFlow,
exposition via API Flask et visualisation avec React.
Stockage des données dans MariaDB et déploiement de l’application avec Docker.
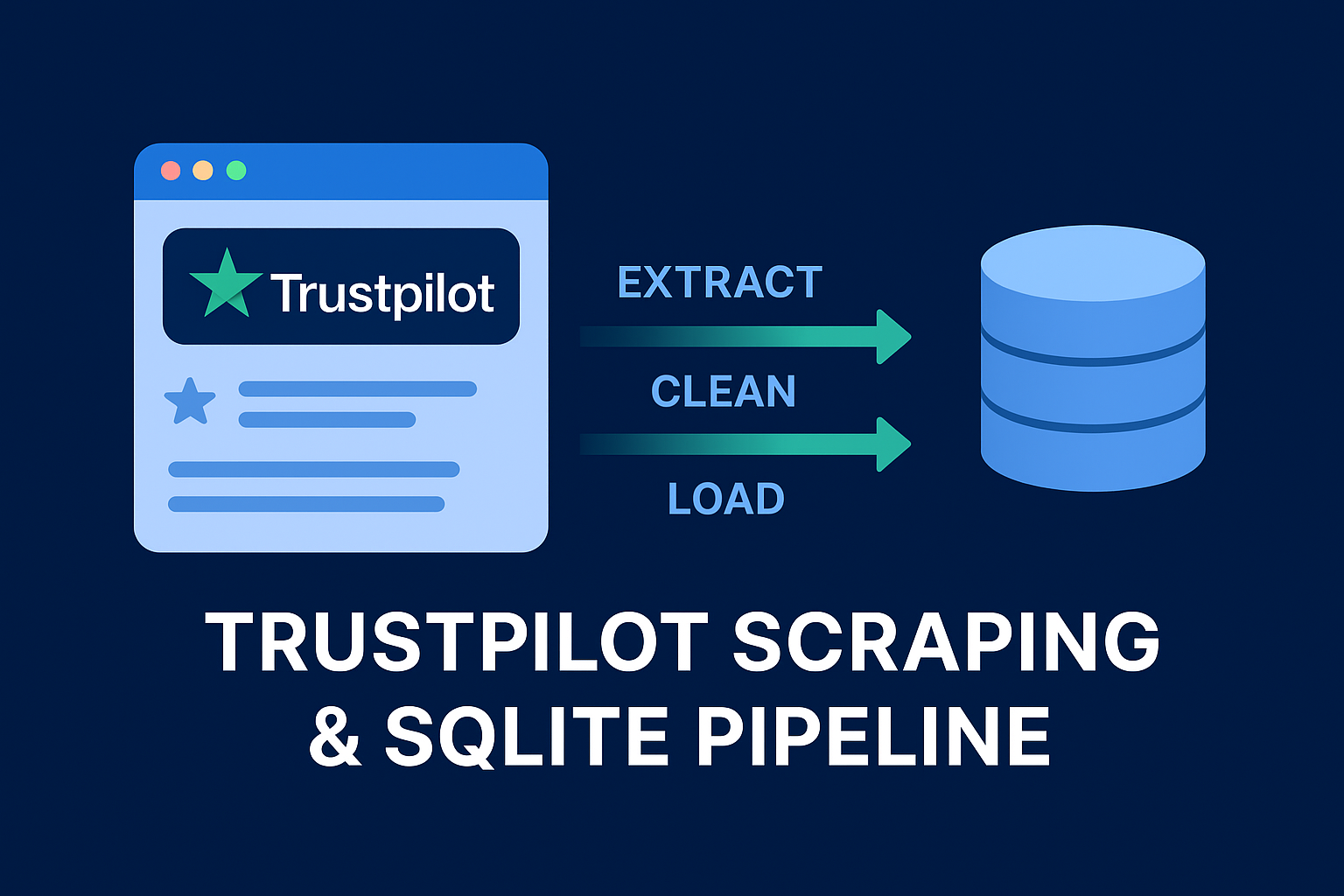
Pipeline ETL de scraping et structuration de données
Développement d’un pipeline ETL de scraping pour collecter, nettoyer et structurer des avis
clients
depuis Trustpilot.
Extraction des données avec Selenium, parsing via BeautifulSoup, nettoyage des données
et suppression des doublons.
Stockage final dans SQLite pour exploitation analytique.
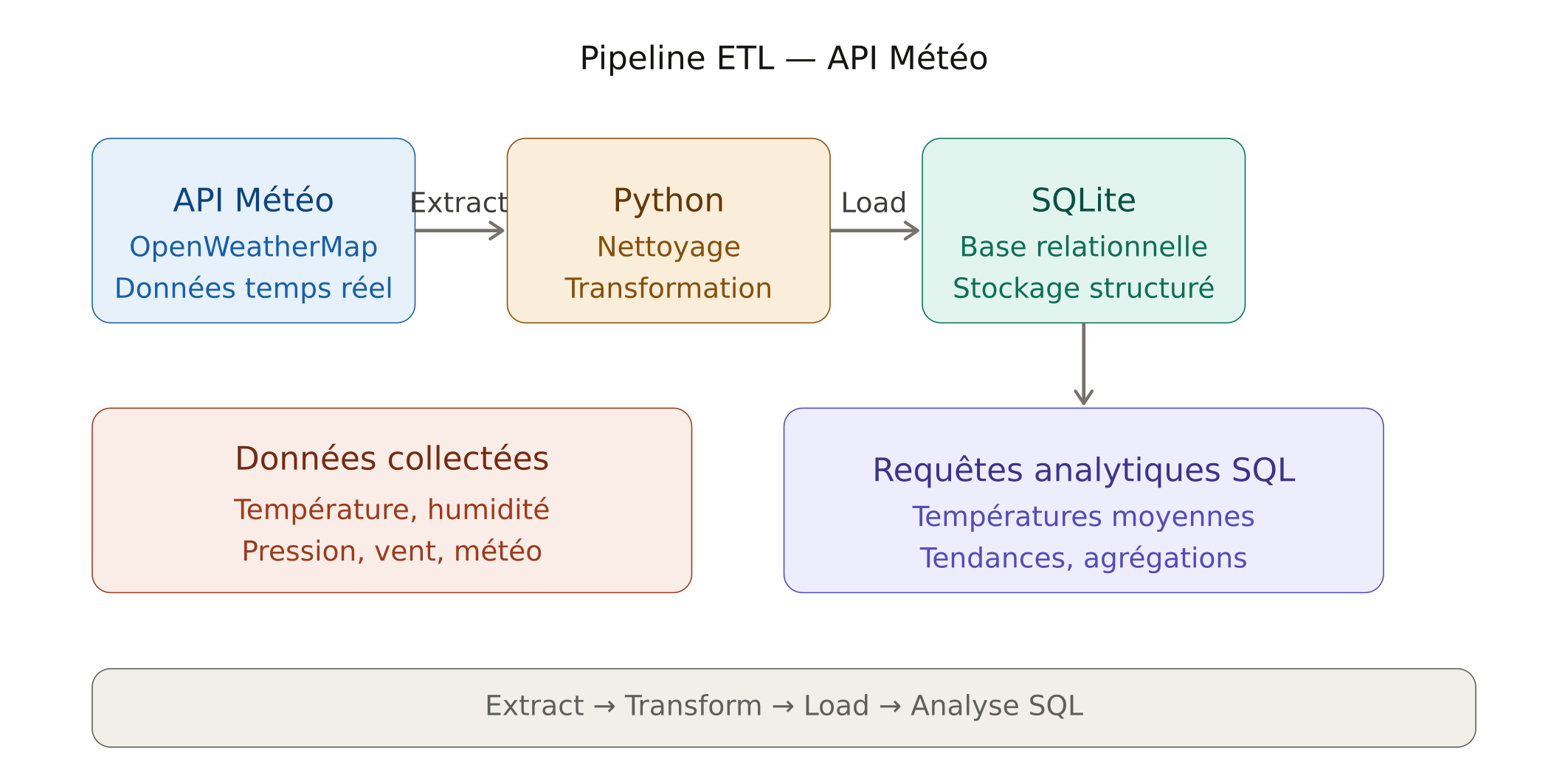
Pipeline ETL API & SQL
Développement d’un pipeline ETL pour collecter et analyser des données météo via
API.
Extraction, transformation et stockage des données dans une base SQL pour exploitation
analytique.
Conception d’une base relationnelle et mise en place de requêtes analytiques pour structurer
et exploiter les données.
Formation
Master Développement, Big Data & Intelligence Artificielle
IPSSI – Lyon, France
- Data Engineering : pipelines ETL, traitement distribué
- Big Data : Spark, Hadoop, Kafka (streaming)
- Architecture Data : Data Lake & Data Warehouse
- Orchestration : Apache Airflow, automatisation
- Cloud : AWS (S3, EMR, Glue)
- DevOps : Docker, CI/CD, Git
Licence Sciences des Données & Développement Informatique
ESTEM – Casablanca, Maroc
- Programmation : Python, Java
- Bases de données : SQL, modélisation relationnelle
- Analyse de données : statistiques, visualisation
- Développement : applications web
Cycle scientifique (PCI)
Université Cheikh Anta Diop – Dakar, Sénégal
- Formation en mathématiques, physique et informatique